Project Overview
This project applies advanced data analysis techniques to a dataset of exchanges, each characterized by over 30 data points, to identify key patterns and provide strategic insights. Due to the sensitive nature of the data, the following is a generalized description of the approach and methodologies employed.
Key Functionalities and Process Flow:
Data Preprocessing:Initial cleaning of the dataset to correct numerical formats, ensuring data integrity for subsequent analysis.
Weighted Ratings Calculation:Computation of nuanced weighted ratings across various platforms to reflect both user sentiment and engagement levels.
Advanced Clustering with K-Means:Employment of K-Means clustering, with manual cluster definition to fulfill specific analysis goals.Clusters are optimized and sorted based on three-month average visitor metrics.Detailed insights are provided for each cluster, highlighting distinctive features and strategic implications.
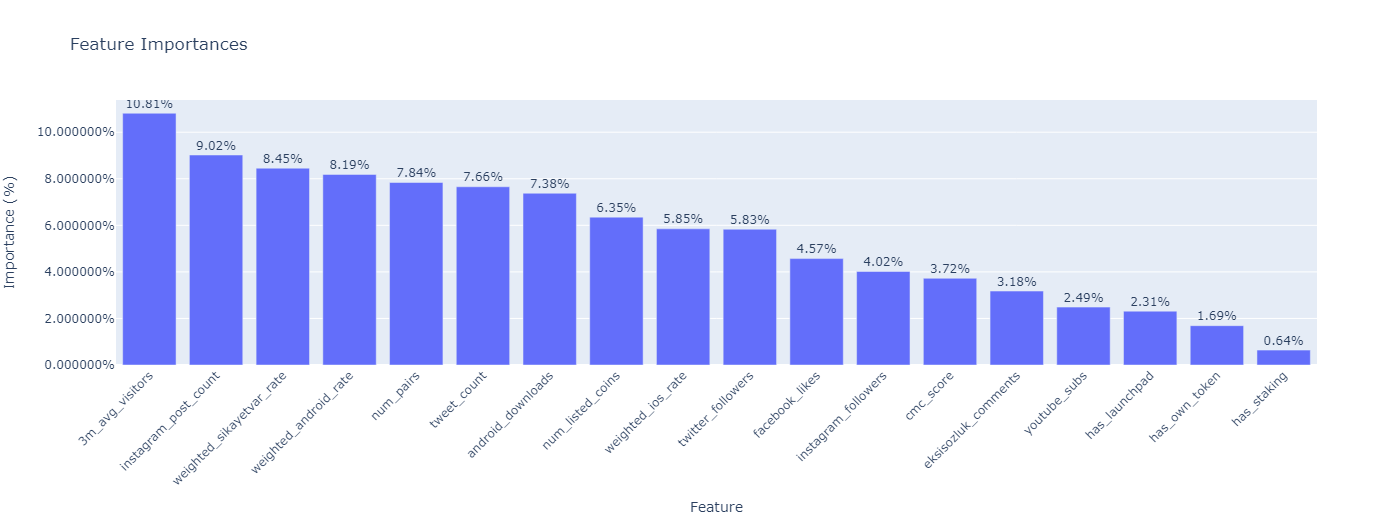
Feature Importance Analysis:Utilization of Random Forest Classifier to evaluate the significance of each feature in the clustering process.
Visualization:Clusters and exchanges are illustrated through a treemap visualization.Feature importances are plotted to convey their impact visually.
Code Structure Overview: Four Primary Classes Defined
1 - DataCleaner
Ensures data integrity by transforming and cleaning DataFrame inputs.
2 - DataProcessor
Calculates weighted metrics, optimizing DataFrame structure.
3 - ClusteringHandler
Implements and refines data segmentation using KMeans clustering.
4 - Reporting
Visualizes data insights and evaluates cluster performance metrics.
Main Function
Outputs
Mean values for each cluster:
Visualizations
Feature Importances
Treemap of Exchanges (Exchange Names Censored)